
集合学习(二):Collection单列集合
1. Collection接口方法的使用
以ArrayList为例:Collection<String> collection = new ArrayList<>();
| 方法 | 描述 |
|---|---|
add(E e) |
向集合中添加元素 |
addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到当前集合中 |
clear() |
清空集合中的所有元素 |
contains(Object o) |
判断集合中是否包含指定元素 |
containsAll(Collection<?> c) |
判断当前集合是否包含指定集合中的所有元素 |
isEmpty() |
判断集合是否为空 |
iterator() |
返回一个用于迭代集合元素的迭代器 |
remove(Object o) |
从集合中移除指定元素 |
removeAll(Collection<?> c) |
从集合中移除包含在指定集合中的所有元素 |
retainAll(Collection<?> c) |
保留当前集合中同时包含在指定集合中的元素 |
size() |
返回集合中元素的数量 |
toArray() |
返回一个包含集合所有元素的数组 |
- add(E e) - 添加元素
Collection<String> collection = new ArrayList<>();
collection.add("Apple");
collection.add("Banana");
collection.add("Cherry");
System.out.println("After add: " + collection);
addAll(Collection<? extends E> c)- 添加多个元素
Collection<String> anotherCollection = new ArrayList<>();
anotherCollection.add("Date");
anotherCollection.add("Elderberry");
collection.addAll(anotherCollection);
System.out.println("After addAll: " + collection);
contains(Object o)- 检查是否包含某元素
System.out.println("Contains 'Banana': " + collection.contains("Banana"));
containsAll(Collection<?> c)- 检查是否包含多个元素
System.out.println("Contains all of anotherCollection: " + collection.containsAll(anotherCollection));
size()- 获取集合大小
System.out.println("Size of collection: " + collection.size());
- isEmpty() - 检查集合是否为空
System.out.println("Is collection empty: " + collection.isEmpty());
remove(Object o)- 移除某元素
collection.remove("Apple");
System.out.println("After remove 'Apple': " + collection);
removeAll(Collection<?> c)- 移除多个元素
collection.removeAll(anotherCollection);
System.out.println("After removeAll anotherCollection: " + collection);
retainAll(Collection<?> c)- 取交集
collection.add("Fig");
collection.add("Grape");
anotherCollection.add("Fig");
collection.retainAll(anotherCollection);
System.out.println("After retainAll anotherCollection: " + collection);
clear()- 清空集合
collection.clear();
System.out.println("After clear: " + collection);
iterator()- 使用迭代器遍历集合
collection.add("Honeydew");
collection.add("Indian Fig");
Iterator<String> iterator = collection.iterator();
System.out.println("Iterating collection:");
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
toArray()- 转换为数组
Object[] array = collection.toArray();
System.out.println("Array from collection:");
for (Object obj : array) {
System.out.println(obj);
}
2. List
2.1 List接口方法的使用
以ArrayList为例:List<String> list = new ArrayList<>();
| 方法 | 描述 |
|---|---|
add(E element) |
在列表末尾添加元素 |
addAll(int index, Collection<? extends E> c) |
在指定索引位置插入集合中的所有元素 |
get(int index) |
返回指定索引处的元素 |
indexOf(Object o) |
返回第一次出现的指定元素的索引 |
lastIndexOf(Object o) |
返回最后一次出现的指定元素的索引 |
remove(int index) |
移除指定索引处的元素 |
set(int index, E element) |
替换指定索引处的元素 |
subList(int fromIndex, int toIndex) |
返回指定范围内的子列表 |
listIterator() |
返回列表的双向迭代器 |
listIterator(int index) |
从指定位置开始返回双向迭代器 |
add(E element)- 添加元素
ArrayListList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
System.out.println("After add: " + list);
add(int index, E element)- 在指定索引添加元素
list.add(1, "Date");
System.out.println("After add at index 1: " + list);
addAll(int index, Collection<? extends E> c)- 在指定索引插入集合
List<String> anotherList = new ArrayList<>();
anotherList.add("Elderberry");
anotherList.add("Fig");
list.addAll(2, anotherList);
System.out.println("After addAll at index 2: " + list);
get(int index)- 获取指定索引的元素
System.out.println("Element at index 2: " + list.get(2));
indexOf(Object o)- 查找元素的首次索引
System.out.println("Index of 'Cherry': " + list.indexOf("Cherry"));
lastIndexOf(Object o)- 查找元素的最后一次索引
list.add(“Cherry”);
System.out.println("Last index of 'Cherry': " + list.lastIndexOf("Cherry"));
remove(int index)- 移除指定索引的元素
list.remove(1);
System.out.println("After remove at index 1: " + list);
set(int index, E element)- 替换指定索引的元素
list.set(1, "Grape");
System.out.println("After set at index 1: " + list);
subList(int fromIndex, int toIndex)- 获取子列表
List<String> subList = list.subList(1, 3);
System.out.println("Sublist (index 1 to 3): " + subList);
listIterator()- 获取双向迭代器
ListIterator<String> listIterator = list.listIterator();
System.out.println("Iterating list using listIterator:");
while (listIterator.hasNext()) {
System.out.println(listIterator.next());
}
listIterator(int index)- 从指定索引获取双向迭代器
ListIterator<String> listIteratorFromIndex = list.listIterator(1);
System.out.println("Iterating from index 1 using listIterator:");
while (listIteratorFromIndex.hasNext()) {
System.out.println(listIteratorFromIndex.next());
}
2.2 ArrayList扩容机制分析
- ArrayList无参构造,扩容机制为,初始化大小10,之后每次扩容以当前大小1.5倍进行扩容
- ArrayList有参构造,扩容机制为,初始化大小为设定值,之后每次扩容以当前大小1.5倍进行扩容
- 扩容机制的核心是grow()方法,
- 当第一次初始化大小,大小为
DEFAULT_CAPACITY(值为10) - 再次扩容,会调用newLength(…)方法,一般情况下为
oldLength + prefGrowth,即:oldLength + oldCapacity >> 1,即:旧值+旧值右移一位,也就旧值的1.5倍
- 当第一次初始化大小,大小为
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
// preconditions not checked because of inlining
// assert oldLength >= 0 // assert minGrowth > 0
int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflow
if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {
return prefLength;
} else {
// put code cold in a separate method
return hugeLength(oldLength, minGrowth);
}
}
2.3 ArrayList与LinkedList的区别
- 如果改查的操作多,选择ArrayList
- 如果增删的操作多,选择LinkedList
| 底层结构 | 增删的效率 | 改查的效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低,数组扩容 | 较高 |
| LinkedList | 双向链表 | 较高,链表追加 | 较低 |
2.4 Vector特点和扩容机制分析
-
Vector与ArrayList的区别不大,只是Vector是线程安全的,而ArrayList是线程不安全的
-
无参构造,扩容机制为,初始化大小为10,之后每次扩容为原来大小的2倍
-
有参构造,扩容机制为,初始化大小为指定大小,之后每次扩容大小为指定的增长值
capacityIncrement -
核心扩容方法grow(),如果指定了增长值,则每次扩容大小为指定的增长值,否则为旧值的两倍
capacityIncrement > 0 ? capacityIncrement : oldCapacity
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
capacityIncrement > 0 ? capacityIncrement : oldCapacity
/* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
}
// 有参构造
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
3. Set
3.1 Set的基本介绍
- 无法添加重复的元素到集合中
- 输出顺序与插入顺序不同,但是固定的插入顺序一定会有固定的输出顺序
3.2 HashSet源码分析
- HashSet底层是HashMap
public HashSet() {
map = new HashMap<>();
}
- 当添加第一个元素时会调用resize()方法,将map.table(底层HashMap的一个属性)大小初始化为
DEFAULT_INITIAL_CAPACITY(16),并设置临界值(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY)(12)
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
- HashSet无法添加重复的元素,底层实现如下
- 代码执行流程,见下方代码注释
- 在判断元素是否相同时,首先看hash值是否相同,接着看equals()方法返回的结果是否为真
- 因此,元素是否是否相同,取决于hashCode()和equals()两个方法的实现
- 对于自定义类,hashCode()和equals()可以进行重写,从而决定是否重复元素
// 判断元素放在那个索引处,以及索引处是否为空,为空的情况就将元素放到索引处
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // 进入else分支,表示索引位置不为空
Node<K,V> e; K k;
/// 判断元素是否与索引处链表的头结点重复
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 不重复,则循环比较元素与链表后续节点是否重复
// 如果链表是红黑树则会进入该else分支(此处表述有问题,仅为了方便理解)
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 如果是链表则会进入该else分支
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 判断是否需要进行树化
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break; }
// 和上方判断是否重复的方法相同
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
- 在插入元素的代码执行的最后,会判断是否已经到达临界值
- 如果到达临界值,将会对table进行扩容
- 新的容量和临界值均为旧值的2倍,
if (++size > threshold)
resize();
// resize()方法部分代码
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
- 在添加元素时,会判断是否进行树化。树化需要满足两个条件
- 链表的值>=8,将调用treeifyBin()方法
- treeifyBin()方法,会判断table的大小是否>=
MIN_TREEIFY_CAPACITY(64) - 满足上述两个条件则进行树化,将链表转为红黑树
if ((e = p.next) == null) { // 判断是否需要进行树化
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 树化
.......
}
}
3.3 LinkedHashSet源码分析
- LinkedHashSet是有顺序的,可以保证插入顺序与遍历顺序一致
- 底层是LinkedHashMap(HashMap的子类)
- 实现大致是数组 + 双链表,数组分别存储双链表的各个节点,由双链表来保证读写顺序的一致
- 其中数组的,扩容机制与HashSet相同
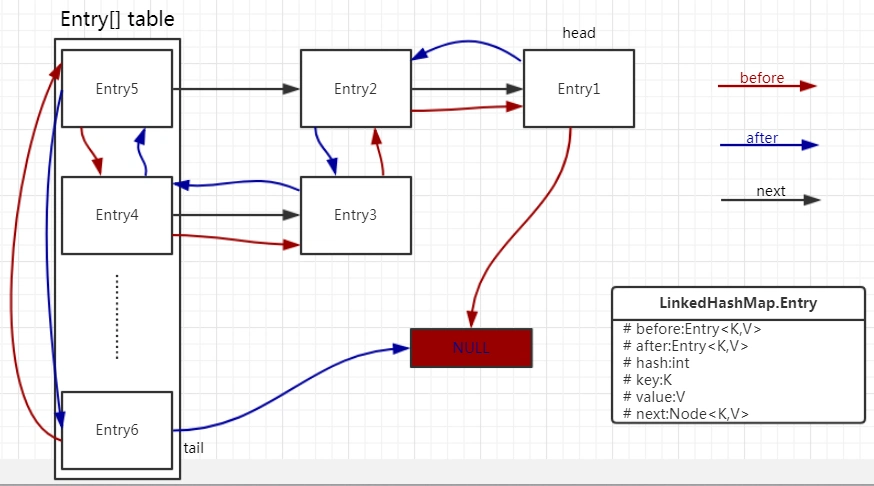
// 当插入新数据时,由于多态会调用LinkedHashMap的newNode()方法实现
// 其会创建一个内部类Entry实例(为HashMap的Node内部类的子类)对新数据进行存储
// 接着调用linkNodeLast()方法将Entry挂载到双链表的末尾
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
本文是原创文章,转载请注明来自 Lazyking.site
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果