
Redis学习(四):实现Feed流Timeline模式
Feed流简单理解
简单理解:Feed流 → 推送流 → 下拉(上拉)刷新
两种模式:
- Timeline: 不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
1. 实现Timeline的三种方式
以用户查看关注的博主更新为例
-
推模式:将博主更新的博客推送到用户收件箱
-
拉模式:当用户查看时,从关注的博主的发件箱获取博文,按照时间排序等处理后,发送到用户收件箱
-
推拉结合:使用算法,对于
cold用户采用拉模式,对于hot用户采用推模式
2. 使用推模式实现关注博主博文推送
2.1 需求分析
- 在保存博文到数据库的同时,需要将其推送到用户收件箱中;
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
存在的问题:
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
问题分析:
假设在t1 时刻,我们去读取第一页,此时page = 1 ,size = 5 ,那么我们拿到的就是10~6 这几条记录,假设现在t2时候又发布了一条记录,此时t3 时刻,我们来读取第二页,读取第二页传入的参数是page=2 ,size=5 ,那么此时读取到的第二页实际上是从6 开始,然后是6~2 ,那么我们就读取到了重复的数据,所以feed流的分页,不能采用原始方案来做。
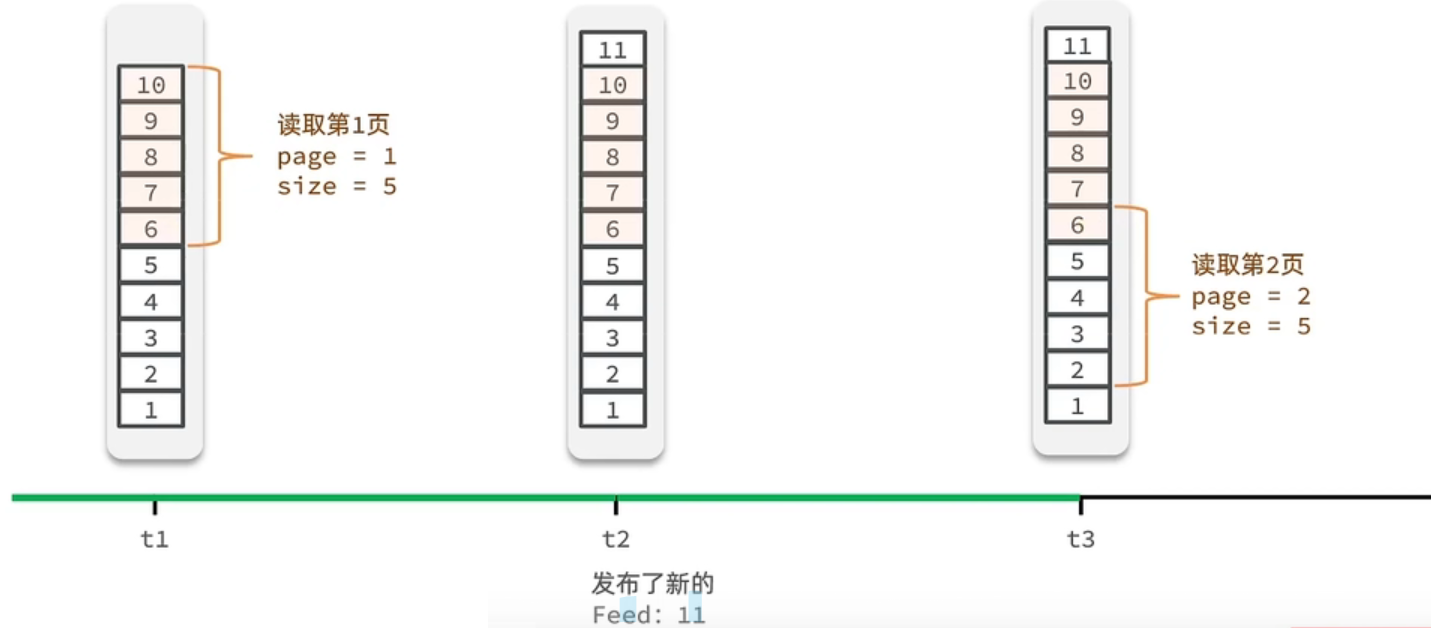
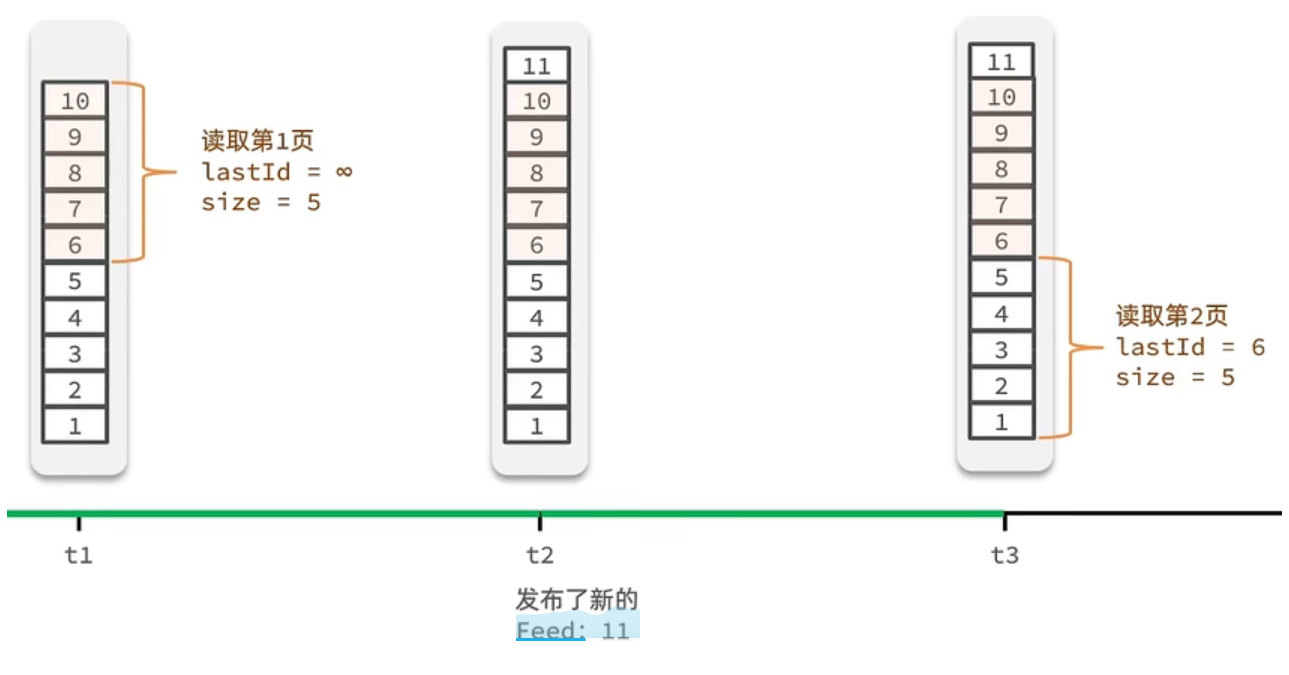
解决方案:
记录每次操作的最后一条,然后从这个位置开始去读取数据。我们从t1时刻开始,拿第一页数据,拿到了10~6,然后记录下当前最后一次拿取的记录,就是6,t2时刻发布了新的记录,此时这个11放到最顶上,但是不会影响我们之前记录的6,此时t3时刻来拿第二页,第二页这个时候拿数据,还是从6后一点的5去拿,就拿到了5-1的记录。我们这个地方可以采用sortedSet来做,可以进行范围查询,并且还可以记录当前获取数据时间戳最小值,就可以实现滚动分页了。
2.2 实现推送
@Override
public Result saveBlog(Blog blog) {
// 1. 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2. 保存探店博文
save(blog);
// 3. 查询关注该博主的用户
List<Follow> followers = followService.query().eq("follow_user_id", user.getId()).list();
// 4. 推送博文到粉丝的收件箱
for (Follow follower : followers) {
String key = FEED_KEY + follower.getId();
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5. 返回id
return Result.ok(blog.getId());
}
2.3 实现分页查询收件箱
难点分析:
- 分析查询出的数据中的最小时间戳,作为下一次查询的最大值
- 找到查询数据中与最小时间错相同的数据个数,作为下次查询的偏移量
- 定义具体的返回值实体类
@Data
public class ScrollResult {
private List<?> list; // 采用泛型,实现通用
private Long minTime;
private Integer offset;
}
- 定义接口
@GetMapping("/of/follow")
public Result queryBlogOfFollow(@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}
- 业务层逻辑
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1. 获取当前用户
Long userId = UserHolder.getUser().getId();
// 2. 查询收件箱 ZREVRANGEBYSCORE KEY MAX MIN LIMIT OFFSET COUNT String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate
.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3. 非空判断
if (typedTuples == null || typedTuples.isEmpty()){
return Result.ok();
}
// 4. 解析数据:blogId,最小时间戳, offset
ArrayList<Long> idList = new ArrayList<>(typedTuples.size());
long minTime = 0; // 最小时间戳
Integer nextOffset = 1; // 偏移量
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
// 4.1 获取id
idList.add(Long.valueOf(typedTuple.getValue()));
// 4.2 获取分数(时间戳)
long time = typedTuple.getScore().longValue();
if (time == minTime) {
nextOffset++;
} else {
minTime = time;
nextOffset = 1;
}
}
nextOffset = minTime == max ? nextOffset : offset + nextOffset;
String idListStr = StrUtil.join(",", idList);
List<Blog> blogList = query().in("id", idList).last("order by field(id, " + idListStr + ")").list();
for (Blog blog : blogList) {
// 5.1 查询blog的作者
queryBlogUser(blog);
// 5.2 查询当前用户是否点赞
isBlogLiked(blog);
}
// 6. 封装ScrollResult,并返回
ScrollResult scrollResult = new ScrollResult(blogList, minTime, nextOffset);
return Result.ok(scrollResult);
}
本文是原创文章,转载请注明来自 Lazyking.site
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果